Recommendation-Systems in python
A Beginner’s Guide with easy to understand example of a movie-recommender system.
The concept of product recommendation on apps like Amazon, Flipkart, Netflix etc is not new to us. Almost all of us have happily experienced it not only on these apps but much earlier than now at mom-and-pop grocery stores where the shopkeeper offered us new items every now and then. But that was easier back then for such stores since the number of products and buyers were only a handful. But what if the numbers run into a couple of millions, we definitely need some help sorting them. In this post we will be looking at the concept which goes by the term Recommender-Systems which helps organizations tell us what we are looking for even before we know what we are looking for. Primarily speaking, Recommender-Systems are algorithms which suggest relevant items to users based on their liking and general trend.
To make this post a real guide for the beginners, we must ensure a straightforward structure and hence it will be broken down into multiple parts.
Index
Part 1 : Introduction and theory
Part 2 : Content based Recommender System in Python
Part 3 : Collaborative Filtering based Recommender System in Python
Part 4 : Association rule mining and Apriori Algorithm
The intent of this post is to keep the explanation as simple as possible and explain as much as possible without going into any complex mathematical concepts. Further, to easy understanding, same dataset will be used to build both content and collaborative filtering based systems.
All codes can be found on the GitHub repository here.
Part 3 and Part 4 have been explained in a separate post, the link to which is here.
Part 1 : Introduction
Recommender-System is an algorithm or information-filtering technique which is used for product/service recommendation to users. The most relatable example would be of ‘Frequently Bought Together’ suggestion at the bottom on Amazon’s page every time you choose a product for a purchase or the list of videos recommended to you on your YouTube home page. Such systems are beneficial to both seller as well as the buyer and its purposes can broadly be outlined as follows
- It predicts to what degree a user likes an item
- It reduces the search time/cost for buyers by suggesting relevant products
- It introduces new products to buyers which they were not aware about
- Improves the conversion rate or basically speaking the sales figures of the seller
- Allows the seller to offer best packages taken out from a ton of data without experiencing information-overload
For any Recommender-system to work, we need to provide it with data which can be collected ‘explicitly’ (user provides the rating for a particular item) or ‘implicitly’ (user just views/clicks on a particular item). As was mentioned above, Recommender-systems are basically filtering systems, and acting true this the data collected from users if filtered using various algorithms to generate recommendations. These filtering algorithms are called Paradigms of Recommender-Systems and are listed below:
- Personalized Recommendations
Such system has been prevalent since older times and all of us have experienced it while walking into a mom-and-pop store where the shop keeper knows us by name and offers us products based on our choices. Such system obviously could not have kept pace with the market growth and also does not consider what our peers like. - Content Based filtering
It is used to recommend similar items liked or viewed by a user before. - Collaborative Filtering
Uses the collected data to consider similarity between users and items simultaneously and hence addresses limitations of the content-based filtering to an extent. - Hybrid
This is a combination of both content based and collaborative filtering methods.

In the next section we will be detailing the two most commonly used methods (also referred to as paradigms) of recommender systems; i.e. Content based filtering and Collaborative filtering.
Part 2 : Content Based Recommender Systems
Content based systems find similarities between items to create recommendations. But how is this similarity calculated? There are multiple ways to work on similarity of items, a few are listed below:
Cosine Similarity : uses the cosine of angle between the vectors
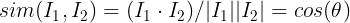

Without going into too much details, let us just keep in mind that cosine(theta) is one of the ways to find the similarity between items, we will see how this can be easily done in python later on.
Euclidean Distance and Pearson’s Coefficient are two more methods to find the similarity. But we will again skip the mathematics behind these as these can be easily implemented in python. If you wish to read more on this, there are some amazing articles on the internet which explain all distance functions in detail. We will be using cosine similarity to build our content based recommender system.
The dataset which we will be using is from Kaggle and can be found here.
movies_df = pd.read_csv('...\\movies.csv')rating_df=pd.read_csv('...\\ratings.csv')
Let us have a look at the data we have

The content-based recommender system will find similarity between content and generate recommendation. For us to build such a system we will have to identify the content and its characteristics. The content here is movies and the characteristics are given by ‘genres’. But that column in not currently in usable form so let us somehow make it useable.
The concept of one-hot encoders or dummification must be known to you. We are going to achieve the same thing here. These are the steps we are going to take
- identify each and every individual genre
- make a list of it
- create empty columns for each identified individual genre
- populate the columns with 1 if the genre is applicable to the movie, else 0 (on hot encoding type logic)
Now, these steps have nothing to do with recommender systems, this is just an attempt to create features which will some how give characteristics of movies. In most of the examples on the internet, you will find NLP (tfidf method) being used for building content based recommender systems. This is because the NLP is used to extract information from the description of the movies given. Essentially it is the same thing as what we are doing here but I have avoided using NLP to keep the explanation simple.
The steps where new columns are made have been included in full code file uploaded on GitHub, I am skipping the part here. So after the step the data base now looks like this.

If you observe you will see that for row 0 (Toy Story) the comedy and fantasy columns have 1 under it since Toy Story has those genres mentioned. This would happen for all genres for a particular movie.
Our database is ready now and we will start building the recommender-system. Here are the steps that we will follow
- Step 1 : Extract only that part of the database which explains the characteristics of movies (from column ‘Comedy’ till end)
- Step 2 : With this extracted dataframe we will create a pair-wise similarity matrix
- Step 3 : create a series of movie names in same order as original dataframe, only the name of movies here will be a index position and the index position number will be the series value
- Step 4 : extract the desired row number from pair-wise similarity matrix generated earlier in form of list or series
- Step 5 : take out top N numbers from the sorted list or series along with there index position
- Step 6 : feed these index position in original database to get the name of recommended movies.
Step 1
Here is what we want

Step 2
For generating pairwise similarity we will use the cosine function available in python
from sklearn.metrics.pairwise import cosine_similarity# Compute the cosine similarity matrix
cosine_sim = cosine_similarity(X = movies_df.iloc[:,3:23])

What has happened here is that for each movie a similarity score has been generated against every other movie based on the various combination of genres. So if a movie has Action and Comedy as genre then it will show a value of 1 for every other movie with same genre combination. If only Action is genre for a movie then the similarity score will be less than 1 and if no matching genres are there then the similarity score will be 0.
So since we had a total of 9742 movies, the similarity matrix will be of 9742 x 9742 (rows will be movie ID and columns will be similarity score in same order as rows for movie ID)

Step 3
#Construct a reverse map of indices and movie titlesmovie_indices = pd.Series(movies_df.index,index=movies_df['title']).drop_duplicates()
Step 4
index_position_of_basemovie = indices['Jumanji (1995)']cosine_sim[index_position_of_basemovie]
The above line of code will give similarity score generated for the movie ‘Jumanji (1995)’ against all 9742 movies. We want the scores to be sorted so that we can take out top N similar movies.
Step 5
sim_scores = list(enumerate(cosine_sim[index_position_of_basemovie]))sim_scores_sorted = sorted(sim_scores,
key=lambda x: x[1], # to sort based on similarity scores
reverse=True)
Step 6
sim_scores_top10 = sim_scores_sorted[1:11]movie_indices_top10 = [i[0] for i in sim_scores_top10]movies_df['title'].iloc[movie_indices_top10]

Here we have our content based recommendations.
Of-course this kind of recommendation is very basic. This can be made better by throwing in description of the movie along with cast and crew name, length of the movie, language of the movie etc. The more features you add the more information the recommender system has to process.
In the next post we will be looking at Collaborative filtering based recommender systems.
